Data Engineering Tools written in Rust
Python is a popular language for data engineers, but it is not the most robust or secure. Data engineering is an essential part of modern software development, and Rust is an increasingly popular programming language for this task. Rust is an efficient language, providing fast computation and low-latency responses with a high level of safety and security. Additionally, it offers a unique set of features and capabilities that make it an ideal choice for data engineering ?!.
Rust also now offers more and more of libraries and frameworks for data engineering. These libraries provide a variety of features and tools, such as data analysis, data visualization, and machine learning, which can make data engineering easier and more efficient.
This blog post will provide an overview of the data engineering tools available in Rust, their advantages and benefits, as well as a discussion on why Rust is a great choice for data engineering.
Table of Contents
DataFusion

DataFusion, based on Apache Arrow, is an SQL query engine that provides the same functionality as Apache Spark and other similar query engines. It provides an efficient way to process data quickly and accurately, by leveraging the power of Arrow as its backbone. DataFusion offers a range of features that enable developers to build advanced applications that can query millions of records at once, as well as to quickly and easily process complex data. In addition, DataFusion provides support for a wide variety of data sources, allowing developers to access the data they need from anywhere.
Highlight features:
- Feature-rich SQL support & DataFrame API.
- Blazingly fast, vectorized, multi-threaded, streaming exec engine.
- Native support for Parquet, CSV, JSON & Avro.
- Extension points: user-defined functions, custom plan & exec nodes. Streaming, async. IO from object stores.
use datafusion::prelude::*;
#[tokio::main]
async fn main() -> datafusion::error::Result<()> {
// create the dataframe
let ctx = SessionContext::new();
let df = ctx.read_csv("tests/example.csv", CsvReadOptions::new()).await?;
let df = df.filter(col("a").lt_eq(col("b")))?
.aggregate(vec![col("a")], vec![min(col("b"))])?
.limit(0, Some(100))?;
// execute and print results
df.show().await?;
Ok(())
}
+---+--------+
| a | MIN(b) |
+---+--------+
| 1 | 2 |
+---+--------+
Polars

Polars is a blazingly fast DataFrames library implemented in Rust which takes advantage of the Apache Arrow Columnar Format for memory management. It's a faster Pandas. You can see at the h2oai's db-benchmark.
This format allows for high-performance data processing, allowing Polars to process data at an impressive speed. With the combination of Rust's performance capabilities and the Apache Arrow Columnar Format, Polars is an ideal choice for data scientists looking for an efficient and powerful DataFrames library.
use polars::prelude::*;
let df = LazyCsvReader::new("reddit.csv")
.has_header(true)
.with_delimiter(b',')
.finish()?
.groupby([col("comment_karma")])
.agg([
col("name").n_unique().alias("unique_names"),
col("link_karma").max()
])
.fetch(100)?;
Highlight features:
- Lazy | eager execution
- Multi-threaded
- SIMD
- Query optimization
- Powerful expression API
- Hybrid Streaming (larger than RAM datasets)
- Rust | Python | NodeJS | ...
Delta Lake Rust

Delta Lake provides a native interface in Rust that gives low-level access to Delta tables. This interface can be used with data processing frameworks such as datafusion, ballista, polars, vega, etc. Additionally, bindings to higher-level languages like Python and Ruby are also available.
Vector.dev
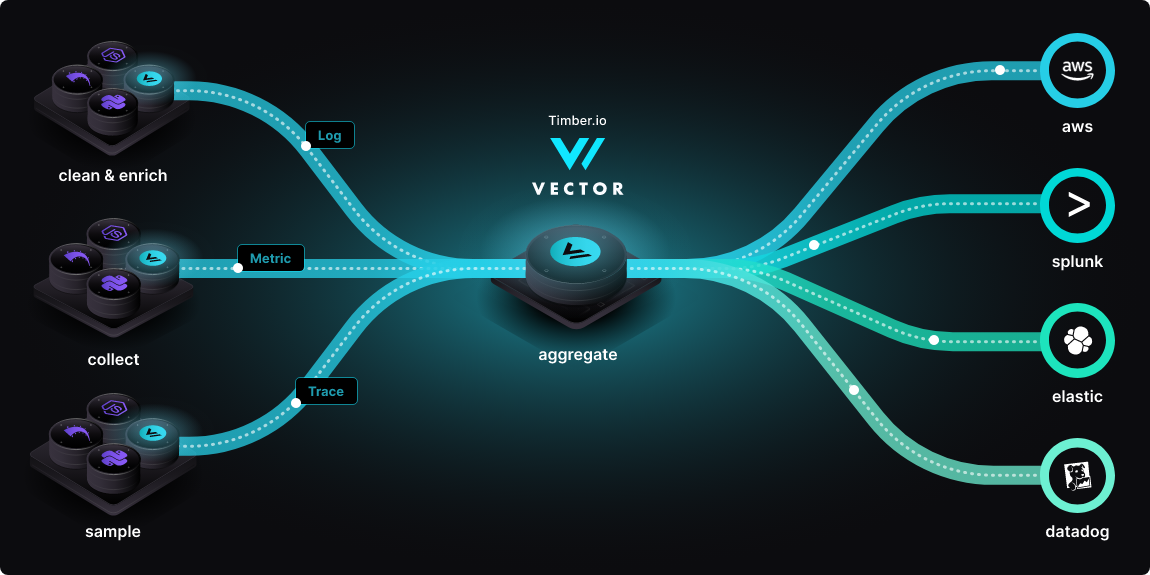
A high-performance observability data pipeline for pulling system data (logs, metadata).
Vector is an end-to-end observability data pipeline that puts you in control. It offers high-performance collection, transformation, and routing of your logs, metrics, and traces to any vendor you choose. Vector helps reduce costs, enrich data, and ensure data security. It is up to 10 times faster than other solutions and is open source.
Vector can be deployed as many topologies to collect and forward data: Distributed, Centralized or Stream based.
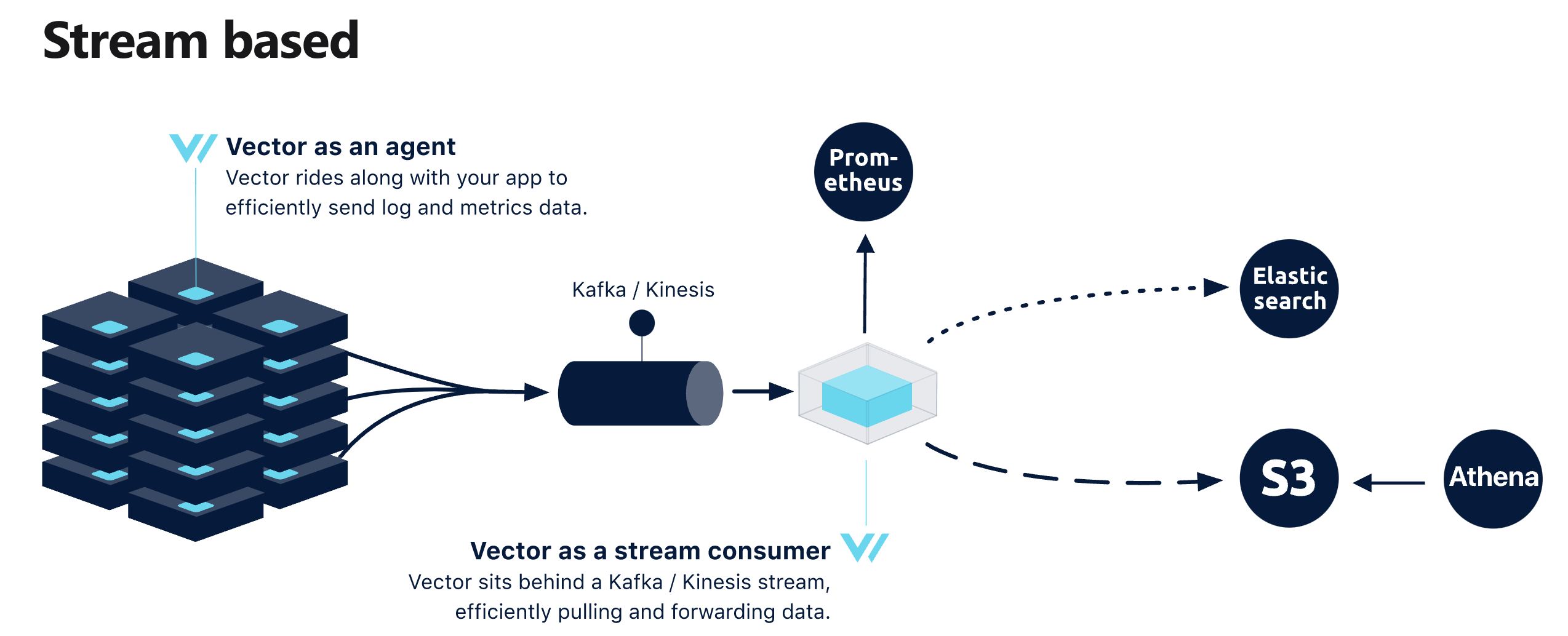
To get started, follow our quickstart guide or install Vector.
Create a configuration file called vector.toml with the following information to help Vector understand how to collect, transform, and sink data.
[sources.generate_syslog]
type = "demo_logs"
format = "syslog"
count = 100
[transforms.remap_syslog]
inputs = [ "generate_syslog"]
type = "remap"
source = '''
structured = parse_syslog!(.message)
. = merge(., structured)
'''
[sinks.emit_syslog]
inputs = ["remap_syslog"]
type = "console"
encoding.codec = "json"
ROAPI
ROAPI automatically spins up read-only APIs for static datasets without requiring you to write a single line of code. It builds on top of Apache Arrow and Datafusion. The core of its design can be boiled down to the following:
- Query frontends to translate SQL, GraphQL and REST API queries into Datafusion plans.
- Datafusion for query plan execution.
- Data layer to load datasets from a variety of sources and formats with automatic schema inference.
- Response encoding layer to serialize intermediate Arrow record batch into various formats requested by client.
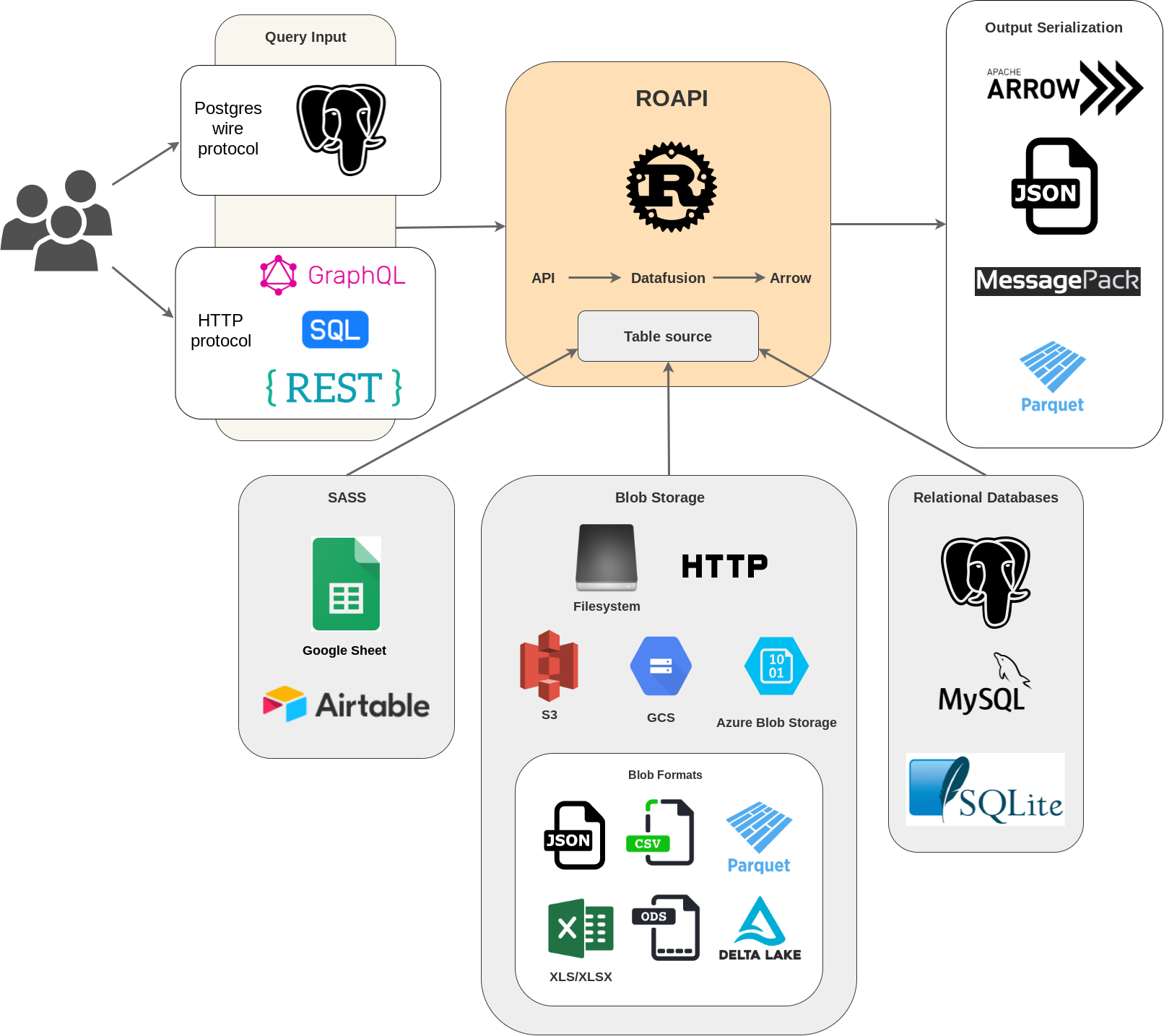
For example, to spin up APIs for test_data/uk_cities_with_headers.csv and test_data/spacex_launches.json:
roapi \
--table "uk_cities=test_data/uk_cities_with_headers.csv" \
--table "test_data/spacex_launches.json"
After that, we can query tables using SQL, GraphQL or REST:
curl -X POST -d "SELECT city, lat, lng FROM uk_cities LIMIT 2" localhost:8080/api/sql
curl -X POST -d "query { uk_cities(limit: 2) {city, lat, lng} }" localhost:8080/api/graphql
curl "localhost:8080/api/tables/uk_cities?columns=city,lat,lng&limit=2"
Cube
Cube is a headless business intelligence platform. It enables data engineers and application developers to access data from modern data stores, organize it into consistent definitions, and deliver it to any application.

Cube is designed to work with all SQL-enabled data sources, such as cloud data warehouses like Snowflake or Google BigQuery, query engines like Presto or Amazon Athena, and application databases like Postgres. It has a built-in relational caching engine that provides sub-second latency and high concurrency for API requests.
Databend
Databend (https://databend.rs) is an open-source, Elastic and Workload-Aware modern cloud data warehouse that focuses on low cost and low complexity for your massive-scale analytics needs.
Databend uses the latest techniques in vectorized query processing to allow you to do blazing-fast data analytics on object storage: (S3, Azure Blob, Google Cloud Storage, Alibaba Cloud OSS, Tencent Cloud COS, Huawei Cloud OBS, Cloudflare R2, Wasabi or MinIO).
Here is the architecture of Databend
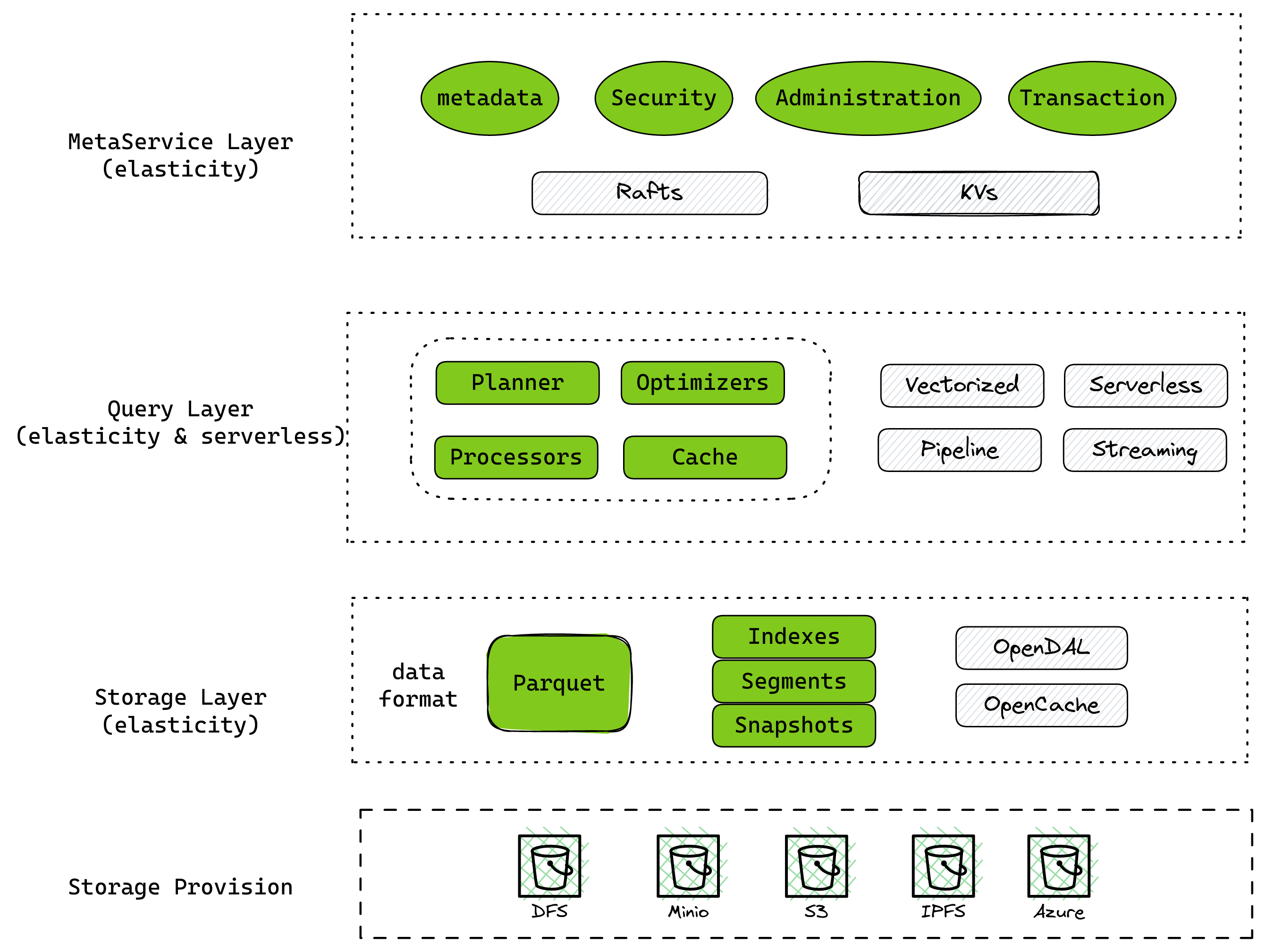
SurrealDB
SurrealDB is a cloud native database for web, mobile, serverless, Jamstack, backend, and traditional apps. It simplifies your database & API stack, removing server-side components and allowing you to build secure, performant apps faster & cheaper. Features include SQL querying, GraphQL, ACID transactions, WebSocket connections, structured/unstructured data, graph querying, full-text indexing, geospatial querying & row-by-row permissions access. Can run as single server or distributed mode.
View the features, the latest releases, the product roadmap, and documentation.
GreptimeDB
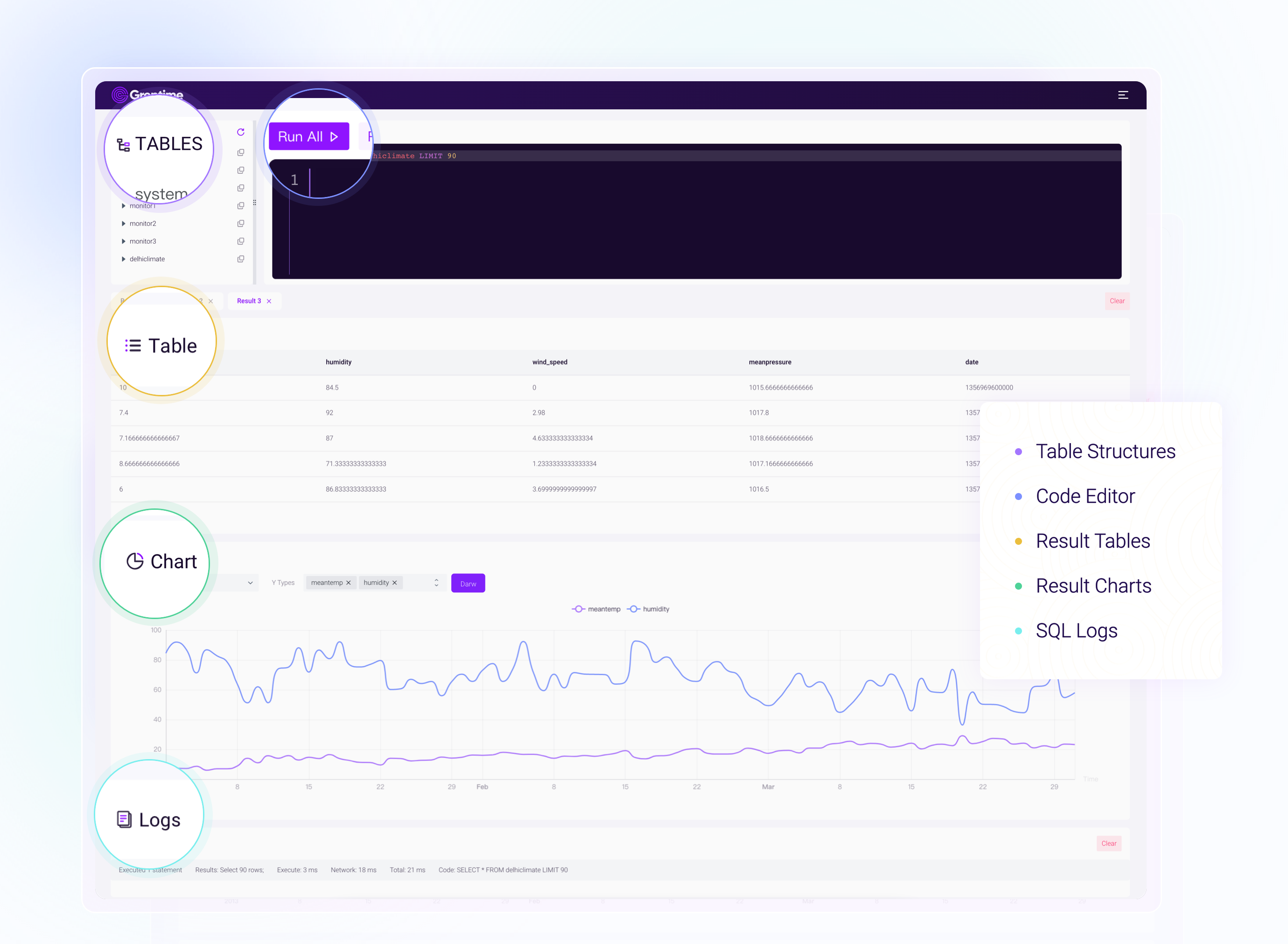
GreptimeDB is an open-source, next-generation hybrid timeseries/analytics processing database in the cloud. It is designed to provide scalability, analytics, and efficiency in modern cloud infrastructure, offering users the advantages of elasticity and cost-effective storage.
Conclusion
There are many more options such as Meilisearch, Tantivy, PRQL, Dozer, Neon, etc. These may be relatively new, but you should give them a try.
At first glance, Rust may seem like an over-engineered choice for data engineering. However, its unique features and capabilities may make it the ideal choice for some data engineering tasks. Rust offers fast computation, low-latency responses, and a high level of safety and security. Additionally, it offers libraries and frameworks for data analysis, data visualization, and machine learning, making data engineering easier and more efficient. With its increasing popularity, Rust is becoming an increasingly attractive option for data engineers.
Series: Rust Data Engineering
Đối với một Data Engineer như mình, ưu tiên chọn một ngôn ngữ dựa trên việc nó có giải quyết được hết hầu hết các nhu cầu và bài toán của mình hay không: Data Engineering, Distributed System và Web Development. Và cuối cùng mình dự định sẽ bắt đầu với Rust, bởi vì ...
This blog post will provide an overview of the data engineering tools available in Rust, their advantages and benefits, as well as a discussion on why Rust is a great choice for data engineering.
If you're interested in data engineering with Rust, you might want to check out Polars, a Rust DataFrame library with Pandas-like API.
My data engineering team at Fossil recently released some of Rust-based components of our Data Platform after faced performance and maintenance challenges of the old Python codebase. I would like to share the insights and lessons learned during the process of migrating Fossil's Data Platform from Python to Rust.