Monitoring ClickHouse on Kubernetes
Now that you have your first ClickHouse instance on Kubernetes and are starting to use it, you need to monitoring and observing what happens on it is an important task to achieve stability. There are many ways:
- Built-in dashboard
- Export metrics to Prometheus and visualize them with Grafana
- ClickHouse Monitoring UI that relies on powerful system tables
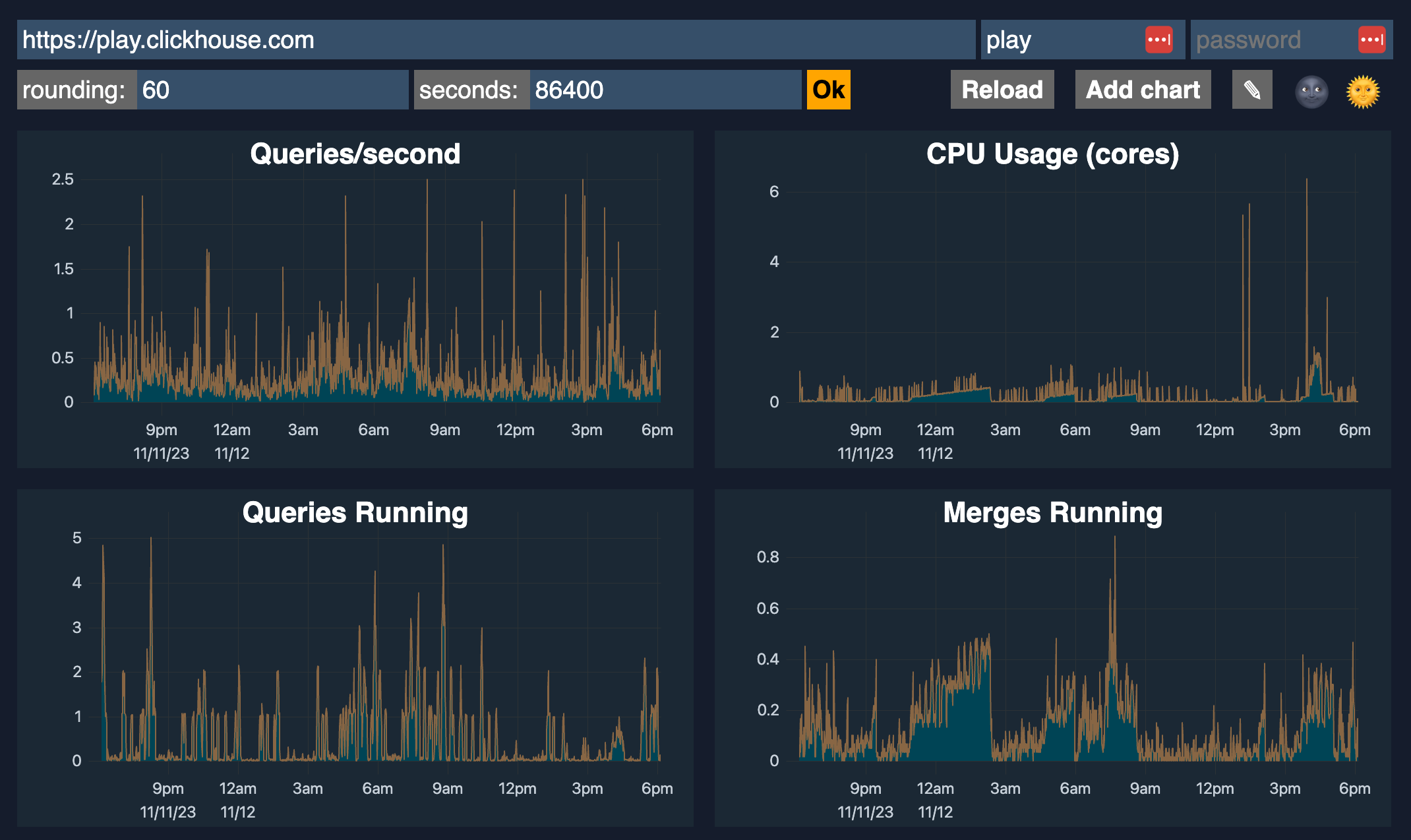
1. Built-in advanced observability dashboard
ClickHouse includes an advanced observability dashboard feature accessible at $HOST:$PORT/dashboard (login required).
It displays metrics such as Queries/second, CPU usage, Queries running, Merges running, Selected bytes/second, IO wait, CPU, Read/Write, Inserted rows/second, Total MergeTree parts, and Max parts for partition, etc.
2. Monitoring with Prometheus + Grafana
You can configure ClickHouse to export metrics to Prometheus. ClickHouse Operator do have a section for this:
- Step 1: Setup Prometheus pool data from ClickHouse into Prometheus
- Step 2: Setup Grafana
They also have a dashboard for ClickHouse Operator Dashboard so you can just need to import it:
- Altinity_ClickHouse_Operator_dashboard.json
- ClickHouse_Queries_dashboard.json
- ClickHouseKeeper_dashboard.json
References:
- ClickHouse Grafana plugin 4.0 - Leveling up SQL Observability
- A Story of Open-source GitHub Activity using ClickHouse + Grafana
- Video: Visualizing ClickHouse Data with Grafana
- Visualizing Data with ClickHouse - Part 1 - Grafana
3. ClickHouse system tables
You should read these blog post by ClickHouse about rely on the system tables to get more insights about running queries and their performance. These contains about some topic like for example: most expensive SELECT queries, average query duration and number of requests, number of SQL queries by client or user, etc.
- Essential Monitoring Queries - part 1 - INSERT Queries
- Essential Monitoring Queries - part 2 - SELECT Queries
4. ClickHouse Monitoring UI Dashboard
This is my simple monitoring dashboard for ClickHouse, built with Next.js for monitoring all my clusters. It relies on system tables above that provide rich information. A live demo is available at: https://clickhouse-monitoring.vercel.app/


You can install it into Kubernetes via the latest helm chart here: https://github.com/duyet/charts/tree/master/clickhouse-monitoring
helm repo add duyet https://duyet.github.io/charts
cat <<EOF >> values.yaml
env:
- name: CLICKHOUSE_HOST
value: http://clickhouse-single.clickhouse.svc:8123
- name: CLICKHOUSE_USER
value: monitoring
- name: CLICKHOUSE_PASSWORD
value: ''
EOF
helm install -f values.yaml clickhouse-monitoring-release duyet/clickhouse-monitoring
Series: ClickHouse on Kubernetes
ClickHouse has been both exciting and incredibly challenging based on my experience migrating and scaling from Iceberg to ClickHouse, zero to a large cluster of trillions of rows. I have had to deal with many of use cases and resolve issues. I have been trying to take notes every day for myself, although it takes time to publish them as a series of blog posts. I hope I can do so on this ClickHouse on Kubernetes series.
Dynamic column selection (also known as a `COLUMNS` expression) allows you to match some columns in a result with a re2 regular expression.
Now that you have your first ClickHouse instance on Kubernetes and are starting to use it, you need to monitoring and observing what happens on it is an important task to achieve stability.
After starting this series ClickHouse on Kubernetes, you can now configure your first single-node ClickHouse server. Let's dive into creating your first table and understanding the basic concepts behind the ClickHouse engine, its data storage, and some cool features
My favorite ClickHouse table engine is `ReplacingMergeTree`. The main reason is that it is similar to `MergeTree` but can automatically deduplicate based on columns in the `ORDER BY` clause, which is very useful.
Now you have a large single node cluster with a ReplacingMergeTree table that can deduplicate itself. This time, you need more replicated nodes to serve more data users or improve the high availability.